はじめに
QualiArts - Qiita Advent Calendar 2024 - Qiita、14日目担当の鈴木光です。アドカレ遅刻して申し訳ありません……
2024年12月03日、AWS re:Invent 2024にてAmazon Aurora DSQLが発表されました。Aurora DSQLは待望のAWSマネージドないわゆるNewSQLに分類されるデータベースです。製品サイトより抜粋してその特徴を簡単に紹介します(回し者ではないです!)
分散 SQL データベース – Amazon Aurora DSQL – AWS
- あらゆるワークロードの需要に合わせて自動的にスケーリング: 読み取り・書き込み・コンピューティング・ストレージを個別に継続的に拡張し、パフォーマンスを維持しながらスケーリングのボトルネックを解消
- アクティブ-アクティブ高可用性: 単一リージョンで 99.99%、マルチリージョンで 99.999% の可用性を実現するように設計
- サーバーレスインフラストラクチャ: マイナー バージョン アップグレード・パッチ適用・セキュリティ更新などの更新を自動的に処理するため、メンテナンスのダウンタイムがない
- PostgreSQL互換: わずかな構成変更で一般的な PostgreSQL ドライバーとツールをサポート
- 分散アーキテクチャ: 単一障害点のないフォールト トレランスを内蔵
- 高いセキュリティ: データベースの認証と承認のために AWS IAMとネイティブに統合され、すべての顧客データは非公開で保存時および転送時に常に暗号化
これまで、この分野ではGoogle CloudのSpannerが業界を席巻していました。SpannerのためにAWSからGoogle Cloudへ移行する事例もある中、この流れに一石を投じるソリューションになるのでしょうか
プレビュー期間は無料ということで、今回はAurora DSQLの負荷試験をしてみました
Aurora DSQLについて
AWSブログとAWS re:Invent 2024のYoutube動画はAurora DSQLを理解する上でとても参考になるので、是非ご覧ください
Amazon Aurora DSQL の紹介
Amazon Aurora DSQL の紹介 | Amazon Web Services ブログ
Amazon Aurora DSQL の同時実行制御
Amazon Aurora DSQL の同時実行制御 | Amazon Web Services ブログ
AWS re:Invent 2024 - Get started with Amazon Aurora DSQL (DAT424)
https://www.youtube.com/watch?v=9wx5qNUJdCE
AWS re:Invent 2024 - Deep dive into Amazon Aurora DSQL and its architecture (DAT427-NEW)
https://www.youtube.com/watch?v=huGmR_mi5dQ
サンプルアプリケーションの実装
ぶっちゃけアドカレに費やした時間は4割がアプリケーションの実装、5割がトレーシング環境の構築、1割で負荷試験となってしましました……
今回は簡単なブログサーバを作っています。"データベース本体のベンチマークを計測するツール" は多いと思うのですが、それをインフラが隠蔽され裏で無制限にスケールするAurora DSQLに打ったところでAWSのインフラの負荷試験になってしまうので、シナリオベースの負荷試験を行うためにサンプルアプリケーションとシナリオを実装しました。なんかいい感じのツールがあれば教えて下さい
実装
Goで実装しました APIサーバの負荷試験をするつもりはないので、HTTPサーバを起動せず擬似的にリクエストを送信してハンドラーの処理内容だけ呼び出しています。また、サーバを実装していた時代の名残も残っていますがあしからず……
テーブル定義
CREATE TABLE IF NOT EXISTS public."users" ( "id" varchar NOT NULL, "name" varchar NOT NULL, "email" varchar NOT NULL UNIQUE, "password_hash" varchar NOT NULL, "created_at" timestamp NOT NULL, "updated_at" timestamp NOT NULL, PRIMARY KEY ("id") ); CREATE TABLE IF NOT EXISTS public."articles" ( "id" varchar NOT NULL, "title" varchar NOT NULL, "body" text NOT NULL, "user_id" varchar NOT NULL, "total_favorite_count" bigint NOT NULL, "created_at" timestamp NOT NULL, "updated_at" timestamp NOT NULL, PRIMARY KEY ("id") -- Aurora DSQLは外部キーをサポートしていない -- FOREIGN KEY ("user_id") REFERENCES "users" ("id") ); CREATE TABLE IF NOT EXISTS public."users_articles" ( "user_id" varchar NOT NULL, "article_id" varchar NOT NULL, "created_at" timestamp NOT NULL, "updated_at" timestamp NOT NULL, PRIMARY KEY ("user_id", "article_id") -- Aurora DSQLは外部キーをサポートしていない -- FOREIGN KEY ("article_id") REFERENCES "articles" ("id"), -- FOREIGN KEY ("user_id") REFERENCES "users" ("id") );
エンドポイント一覧
8つのエンドポイントを実装しています。ユーザー登録API以外はミドルウェアにて認証のクエリが発行されることに注意してください
| メソッド | パス | 処理内容 |
|---|---|---|
| POST | /user | ユーザー登録を行う |
| GET | /articles | 直近投稿された記事を100件取得する。created_atにはインデックスを貼っておらず、テーブルスキャンが入る(はず) |
| GET | /article/:article_id | 記事詳細を取得する |
| POST | /article | 記事を投稿する |
| PATCH | /article/:article_id | 記事を編集する |
| DELETE | /article/:article_id | 記事を削除する |
| GET | /favorite/articles | お気に入り一覧を取得する。IN句の値にはサブクエリを使う |
| POST | /favorite/article/:article_id | 記事をお気に入り登録し、記事側のtotal_favorite_countをインクリメントする(ここが競合要素になる) |
負荷試験シナリオ
シナリオとしては以下のような設定をしています
1. ユーザー登録 2. 90%の確率で記事作成し、以下を最大5回繰り返す 2-1. 50%の確率で記事一覧を取得 2-2. 50%の確率で記事詳細を取得 2-3. 20%の確率で記事を更新 2-4. 1%の確率で記事を削除 3. 50%の確率でお気に入り一覧を取得 4. 50%の確率でセットアップで用意された記事をお気に入り登録 4-1. IDの配列からIDを受取り、お気に入り登録する 4-2. 10%の確率で継続
負荷試験環境の構築
インフラのセットアップ
Aurora DSQLのシングルリージョンクラスターとマルチリージョンクラスターで検証してみました。シングルリージョンクラスターの作成方法は割愛します
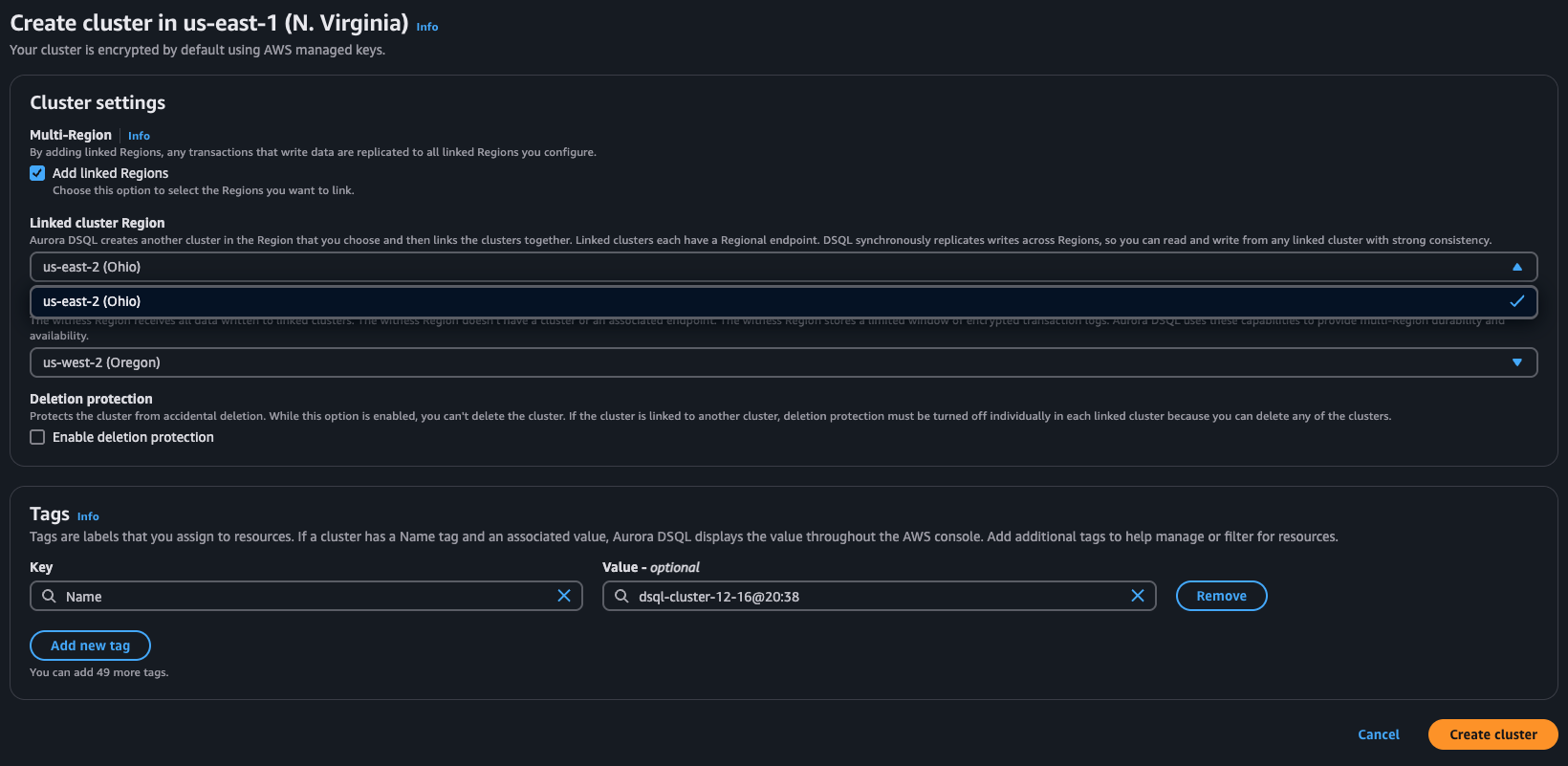
まず us-east-1(バージニア北部) に対してクラスターを作成します。Linked Clusterとして us-west-2(オハイオ) 、ウィットネスリージョンとして us-west-2(オレゴン) を指定し、クラスターを起動します。設定項目は本当にこれだけです。Create clusterを押し、数分したらActiveになります
右上の Connect ボタンを押すと、ホスト名(エンドポイント)、ポート番号、データベース名、パスワード(認証トークン)を確認できます。パスワードは15分の期限があり、再取得が必要です。本来はそのあたりまで自動化するべきですが、今回は期限が切れたらここに取りに来るというスタンスで作業しています
次に us-east-1(バージニア北部) へEC2インスタンスを建てます。AmazonLinux、t2.xlarge なインスタンスを適当に作成しました。SSHキーを登録し、セキュリティグループを設定してSSH出来るようにしておきます。インスタンスを起動したら負荷試験ツール兼サンプルアプリケーションをビルドしたバイナリをSCPコマンドで転送し、SSHしてpsqlでDDLを流すのですが、SSHする際はリモートポートフォワーディングを行います。EC2にトレース環境を構築するのが面倒だったので、EC2で実行したトレースをローカルに送信しています。最後にバイナリを実行して負荷試験を行います
コマンドを以下に添付しましたので、よければ参考にしてください
$ GOOS=linux GOARCH=amd64 go build -o bin . # ソースコードから負荷試験ツールのバイナリをビルド $ scp -i <SSHキー.pem> ./bin ec2-user@<EC2のPublicIPアドレス>:/home/ec2-user # バイナリをSCPコマンドで転送 $ ssh -i <SSHキー.pem> -R 4317:127.0.0.1:4317 ec2-user@<EC2のPublicIPアドレス> # リモートポートフォワーディングしつつSSH $ sudo dnf update -y $ sudo dnf install postgresql16 $ export PGSSLMODE=require $ export PGHOST=<コンソールで取得したホスト名> $ export PGPASSWORD=<コンソールで取得したパスワード> $ psql --quiet --username admin --dbname postgres $ postgres=> CREATE DATABASE blog; $ postgres=> \c blog $ postgres=> <ddl.sqlの内容を貼り付ける> $ postgres=> exit $ DB_HOST=$PGHOST DB_USER=admin DB_PASS=$PGPASSWORD DB_NAME=postgres OTEL_EXPORTER_OTLP_ENDPOINT=http://127.0.0.1:4317 APP_DURATION=180 APP_USERS=10 APP_SPAWN_RATE=1 ./bin # 3分間、最大同時10ユーザー、1秒間に1ユーザーずつユーザーを追加するという設定で負荷試験を実行で負荷試験を実行
OpenTelemetry&Jaeger&Tempoによる計測とJaeger&Grafanaを使った可視化
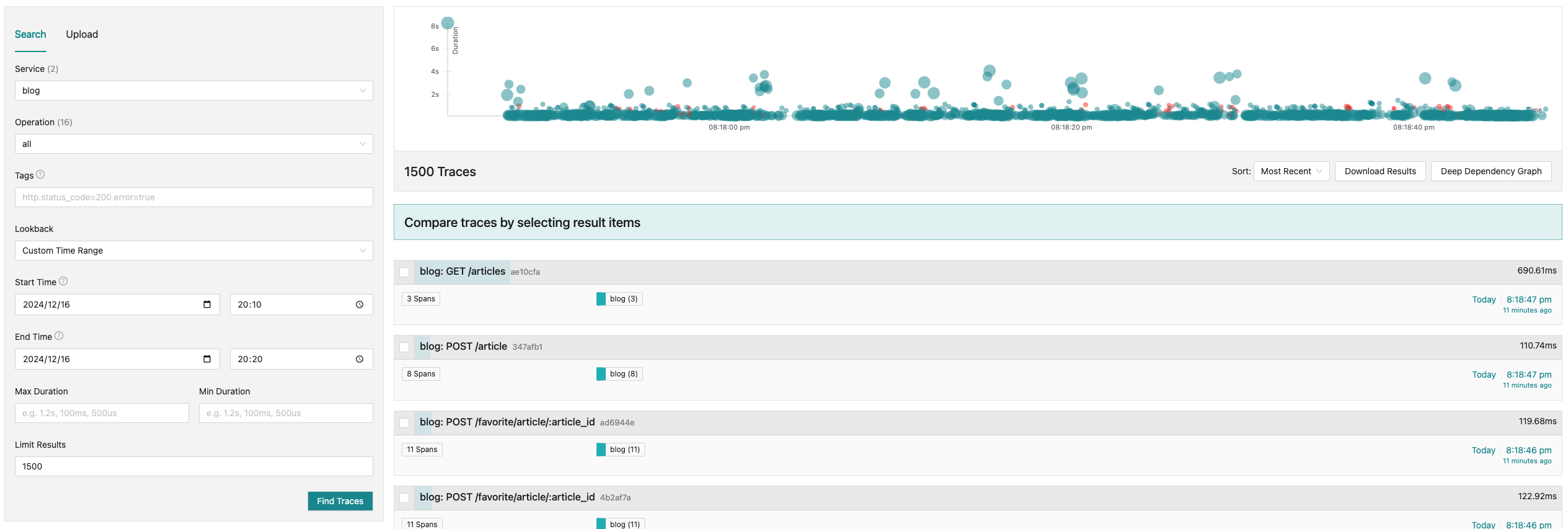
このサンプルアプリケーションにはクエリを発行する部分にトレーサーを仕込んでいます。トレーシングデータはOpenTelemetry Collectorに集約され、Exporterとして登録しているJaegerとTempoに送られます。これをJaeger UIやGrafanaを使って可視化しました
最初はJaguarのSPMだけで完結するかと思ったのですが、レイテンシが95パーセンタイルでしか確認できなかったのでTempoと併用する形にしています。逆にTempo(Grafana)では各Traceを分布図の形でプロットする方法がわからなかったので、こちらで統一ともいきませんでした(ご存じの方教えて欲しいです)
ちなみにJaegerのストレージバックエンドとしてOpenSearchを使っています。本当はJaeger組み込みのローカルファイルストレージであるBadgerを使いたかったのですが、 SPAN_STORAGE_TYPE: badger と METRICS_STORAGE_TYPE: prometheus を同時に設定するとエラーになってJaegerが起動しないという現象に遭遇したためOpenSearchを使うことにしました
負荷試験の実施と結果
APP_DURATION=180 APP_USERS=10 APP_SPAWN_RATE=1 ./bin # 3分間、最大同時10ユーザー、1秒間に1ユーザーずつユーザーを追加するという設定で負荷試験を実行
上記の通り負荷試験の設定が結構甘いのですが、やはりしっかりした環境ではないからかエラー率が上がってしまってこの数値に調整しました。このあたりのチューニングもしっかりしたいところですが、アドカレなのでご容赦を……
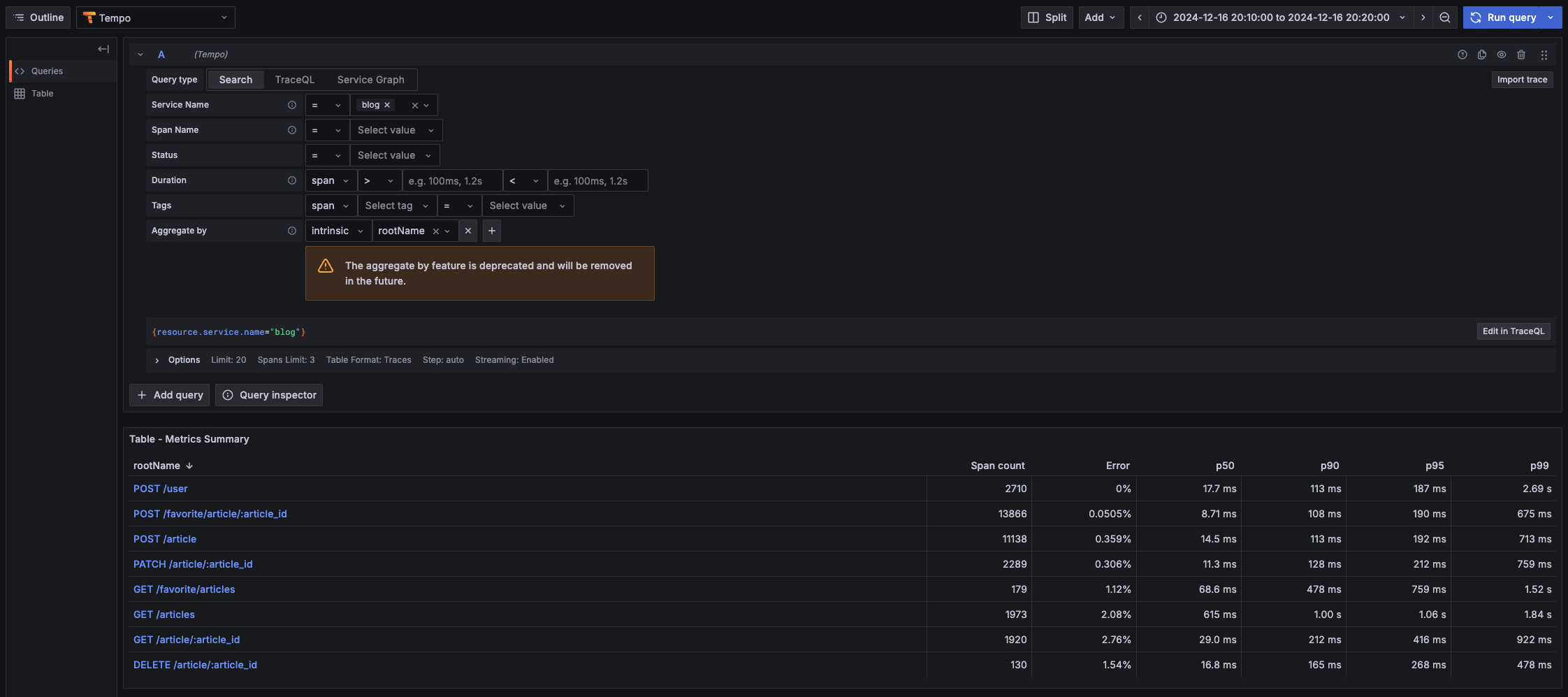
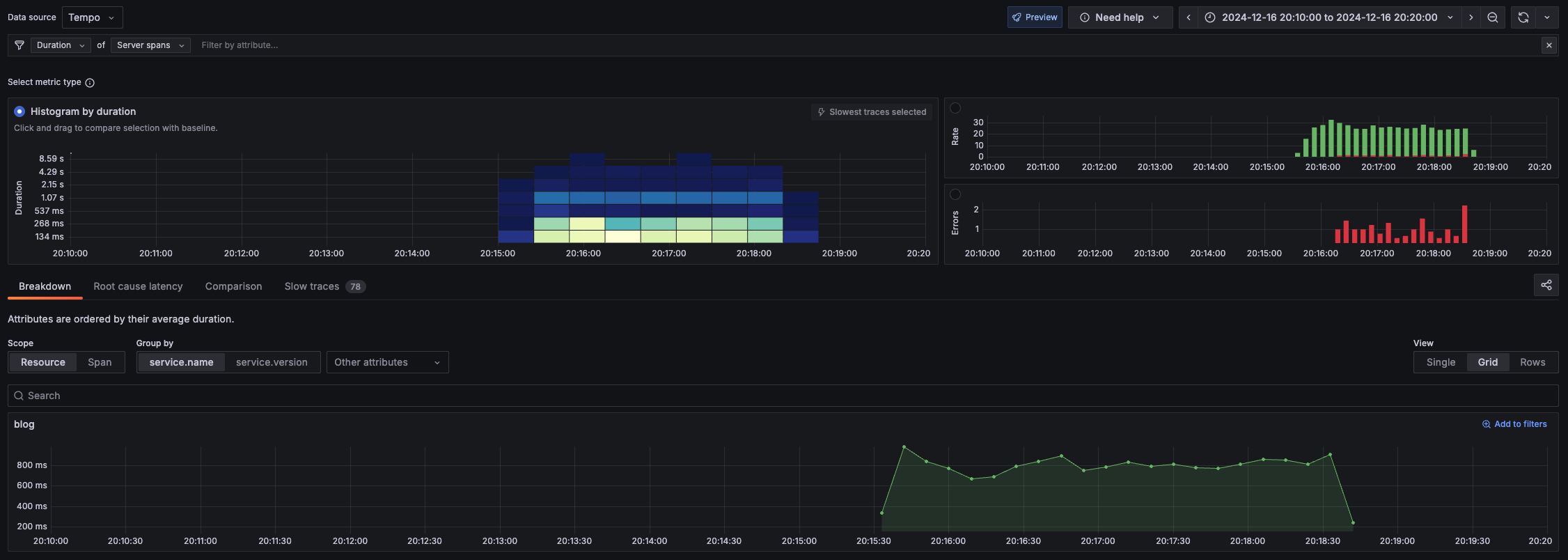
実行してみた所、発表通り楽観的同時実行制御を行っているようでコミット時に衝突してエラーということがよく起こりました。なのでトランザクションを貼る部分にリトライ機構を入れてみたところ、エラーでレスポンスが返るケースはほとんど無くなったのですが、その代わり内部でリトライ祭りになっているのか遅いトランザクションが頻発するようになりました。SpanのAttributesにトランザクション実行回数を加えて分析した所、やはり POST /favorite/article/:article_id APIが多かったです
シングルリージョンクラスター
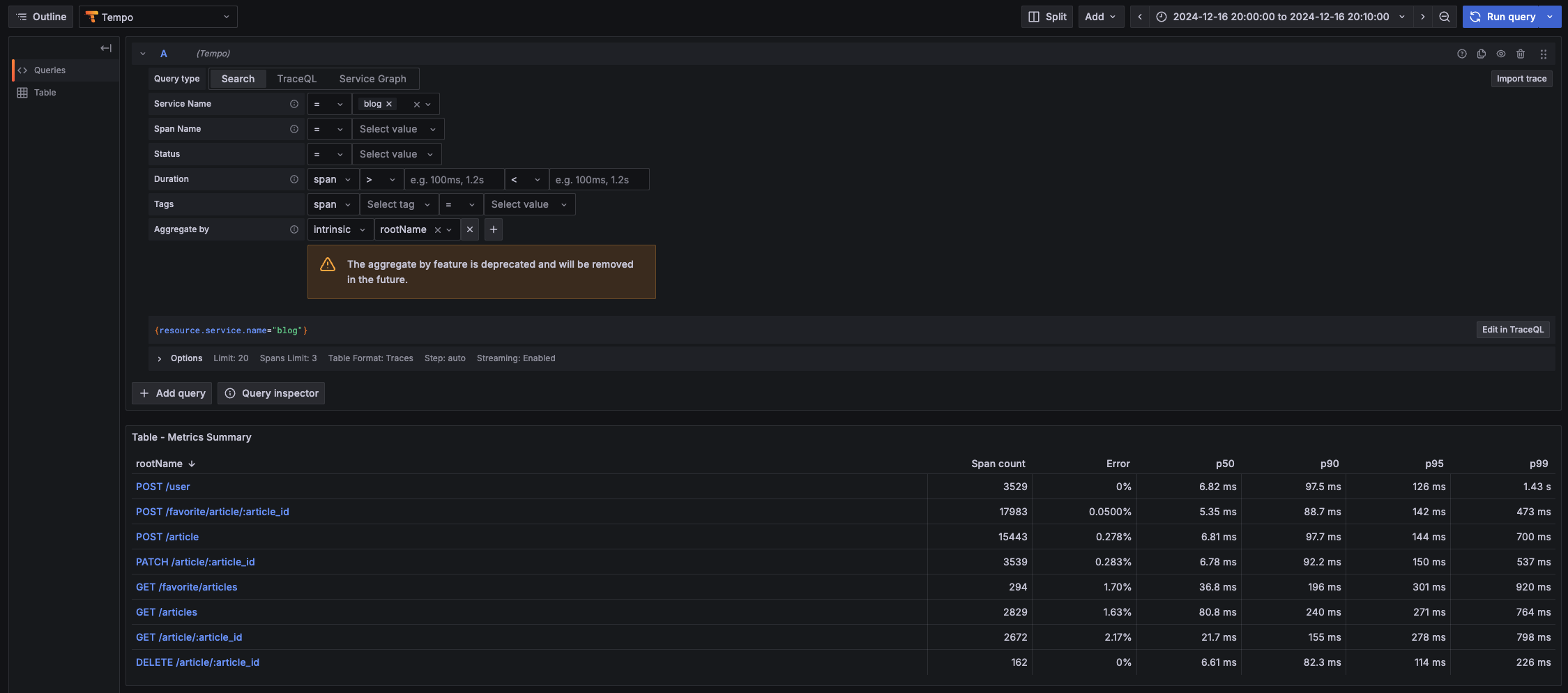
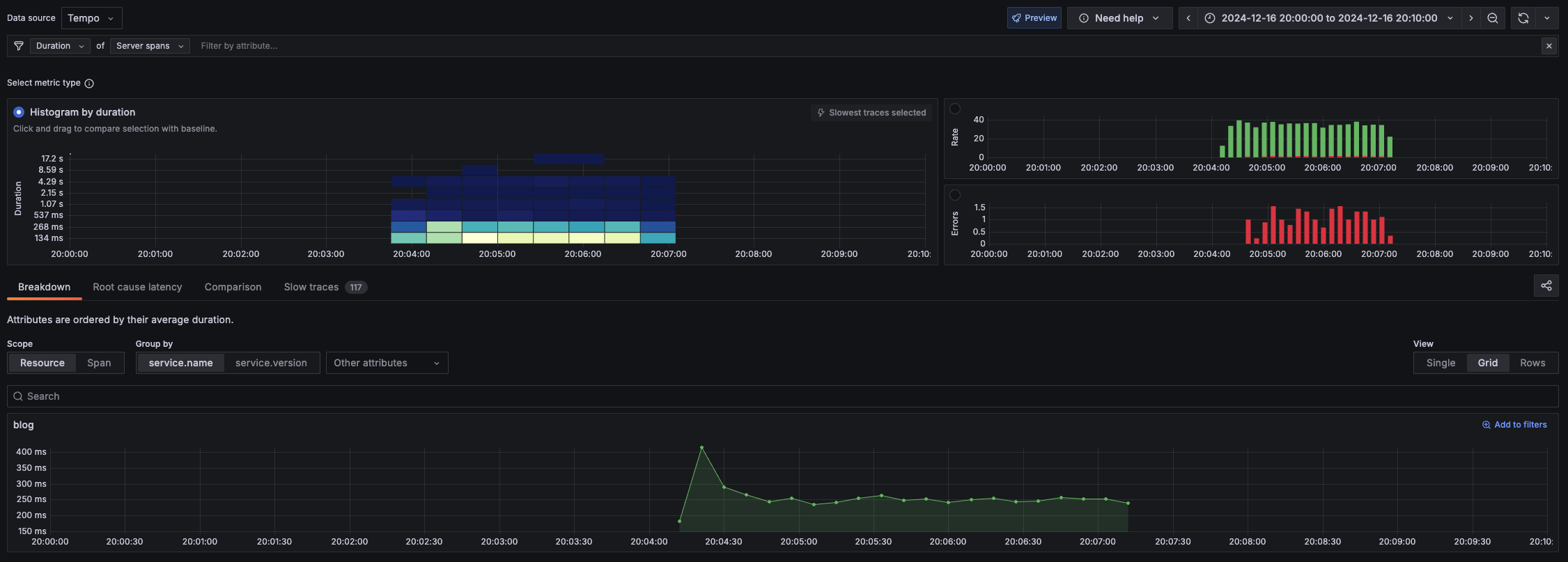
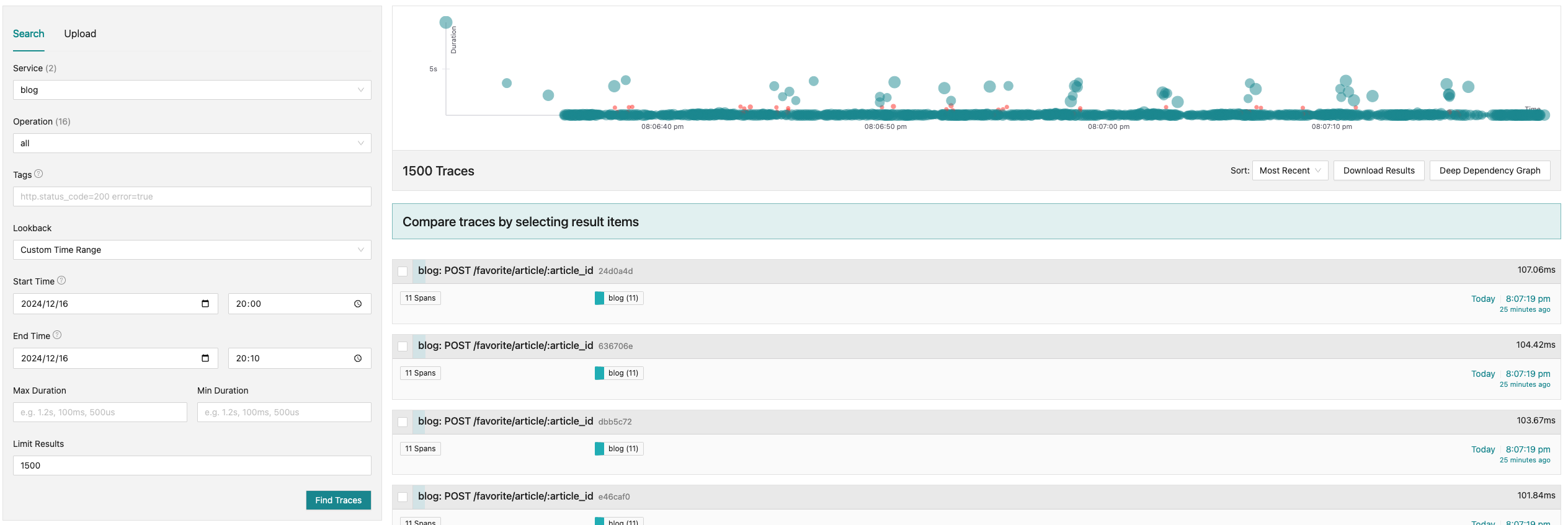
マルチリージョンクラスター
結果
やはりマルチリージョンクラスターのほうがレイテンシが悪い傾向にありますね。特に50パーセンタイルでみると全然違うことがわかります。ただ色々出てきた値を見ている感じ、Spannerより速いという謳い文句は嘘ではなさそうなレイテンシをしていました
ちゃんと検証するなら……
- マルチリージョンからの書き込み: マルチリージョンクラスターに対し、このアプリケーションを
us-east-1(バージニア北部)とus-west-2(オハイオ)から同時に負荷試験したほうがもっとそれっぽい検証になるのですが、競合要素の初期データ作成が面倒だったので今回はやっていません。本格的に検証する際はこういう部分も検証したいですね - 負荷試験環境・設定のチューニング: 単一サーバから行っているため、負荷試験の設定を上げるとエラー率が上がってDBコネクション数なども詰まっている印象がありました
まとめ
アドカレだしレイテンシを計測するくらいでネタになるだろうと思っていたら、結構沼ってしまって一番重要な部分が雑になった気もしなくもないですが、この週末で分散トレーシングについてはかなり身についた気がします。それだけでも良しとしましょう
とはいえちゃんとスケジュールは守らないとですね